In this third article in the series, we discuss adding one or more Jenkins slave nodes to the external OpenStack testing platform that you (hopefully) set up in the second article in the series. The Jenkins slave nodes we create today will run Devstack and execute a set of Tempest integration tests against that Devstack environment.
[toc]
Add a Credentials Record on the Jenkins Master
Before we can add a new slave node record on the Jenkins master, we need to create a set of credentials for the master to use when communicating with the slave nodes. Head over to the Jenkins web UI, which by default will be located at http://$MASTER_IP:8080/. Once there, follow these steps:
- Click the
Credentialslink on the left side panel - Click the link for the Global domain:

- Click the
Add credentialslink - Select
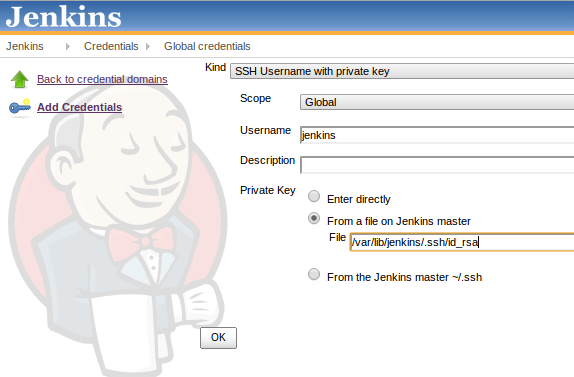
SSH username with private keyfrom the dropdown labeled “Kind” - Enter “jenkins” in the
Usernametextbox - Select the “From a file on Jenkins master” radio button and enter
/var/lib/jenkins/.ssh/id_rsain the File textbox:
- Click the
OKbutton
Construct a Jenkins Slave Node
We will now install Puppet and the software necessary for running Devstack and Jenkins slave agents on a node.
Slave Node Requirements
On the host or virtual machine that you have selected to use as your Jenkins slave node, you will need to ensure, like the Jenkins master node, that the node has the following:
- These basic packages are installed:
- wget
- openssl
- ssl-cert
- ca-certificates
- Have the SSH keys you use with GitHub in
~/.ssh/. It also helps to bring over your~/.ssh/known_hostsand~/.ssh/configfiles as well. - Have at least 40G of available disk space
.
IMPORTANT NOTE: If you were considering using LXC containers for your Jenkins slave nodes (as I originally struggled to use)…. Use a KVM or other non-shared-kernel virtual machine for the devstack-running Jenkins slaves. Bugs like the inability to run open-iscsi in an LXC container make it impossible to run devstack inside an LXC container.
Download Your Config Data Repository
In the second article in this series, we went over the need for a data repository and, if you followed along in that article, you created a Git repository and stored an SSH key pair in that repository for Jenkins to use. Let’s get that data repository onto the slave node:
git clone $YOUR_DATA_REPO data
Install the Jenkins software and pre-cache OpenStack/Devstack Git Repos
And now, we install Puppet and have Puppet set up the slave software:
wget https://raw.github.com/jaypipes/os-ext-testing/master/puppet/install_slave.sh bash install_slave.sh
Puppet will run for some time, installing the Jenkins slave agent software and necessary dependencies for running Devstack. Then you will see output like this:
Running: ['git', 'clone', 'https://git.openstack.org/openstack-dev/cookiecutter', 'openstack-dev/cookiecutter'] Cloning into 'openstack-dev/cookiecutter'... ...
Which indicates Puppet done and a set of Nodepool scripts are running to cache upstream OpenStack Git repositories on the node and prepare Devstack. Part of the process of preparing Devstack involves downloading images that are used by Devstack for testing. Note that this step takes a long time! Go have a beer or other beverage and work on something else for a couple hours.
Adding a Slave Node on the Jenkins Master
In order to “register” our slave node with the Jenkins master, we need to create a new node record on the master. First, go to the Jenkins web UI, and then follow these steps:
- Click the
Manage Jenkinslink on the left - Scroll down and click the
Manage Nodeslink - Click the
New Nodelink on the left:
- Enter “devstack_slave1” in the
Node nametextbox - Select the
Dumb Slaveradio button:

- Click the
OKbutton - Enter 2 in the
Executorstextbox - Enter “/home/jenkins/workspaces” in the
Remote FS roottextbox - Enter “devstack_slave” in the
Labelstextbox - Enter the IP Address of your slave host or VM in the
Hosttextbox - Select jenkins from the
Credentialsdropdown:

- Click the
Savebutton - Click the
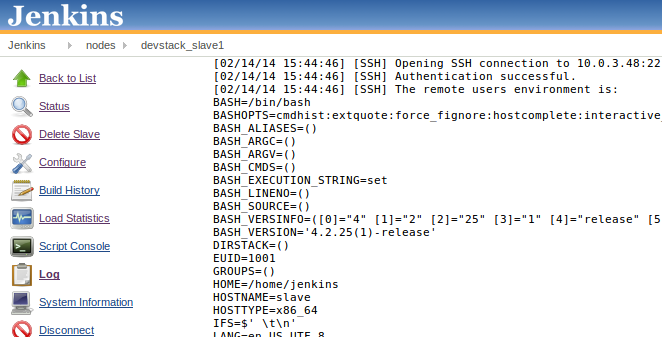
Loglink on the left. The log should show the master connecting to the slave, and at the end of the log should be: “Slave successfully connected and online”:
Test the dsvm-tempest-full Jenkins job
Now we are ready to have our Jenkins slave execute the long-running Jenkins job that uses Devstack to install an OpenStack environment on the Jenkins slave node, and run a set of Tempest tests against that environment. We want to test that the master can successfully run this long-running job before we set the job to be triggered by the upstream Gerrit event stream.
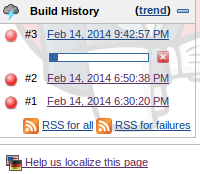
Go to the Jenkins web UI, click on the dsvm-tempest-full link in the jobs listing, and then click the Build Now link. You will notice an executor start up and a link to a newly-running job will appear in the Build History box on the left:
Click on the link to the new job, then click Console Output in the left panel. You should see the job executing, with Bash output showing up on the right:
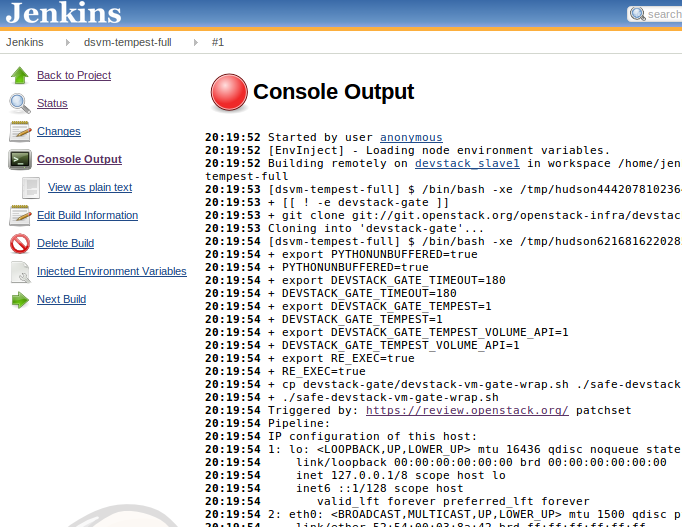
Troubleshooting
If you see errors pop up, you will need to address those issues. In my testing, issues generally were around:
- Firewall/networking issues: Make sure that the Jenkins master node can properly communicate over SSH port 22 to the slave nodes. If you are using virtual machines to run the master or slave nodes, make sure you don’t have any iptables rules that are preventing traffic from master to slave.
- Missing files like “No file found: /opt/nodepool-scripts/…”: Make sure that the
install_slave.shBash script completed successfully. This script takes a long time to execute, as it pulls down a bunch of images for Devstack caching. - LXC: See above about why you cannot currently use LXC containers for Jenkins slaves that run Devstack
- Zuul processes borked: In order to have jobs triggered from upstream, both the
zuul-serverandzuul-mergeprocesses need to be running, connecting to Gearman, and firing job events properly. First, make sure the right processes are running:# First, make sure there are **2** zuul-server processes and # **1** zuul-merger process when you run this: ps aux | grep zuul # If there aren't, do this: sudo rm -rf /var/run/zuul/* sudo service zuul start sudo service zuul-merger start
Next, make sure that the Gearman service has registered queues for all the Jenkins jobs. You can do this using telnet (4730 is the default port for Gearman):
ubuntu@master:~$ telnet 127.0.0.1 4730 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. status build:noop-check-communication:master 0 0 2 build:dsvm-tempest-full 0 0 1 build:dsvm-tempest-full:devstack_slave 0 0 1 merger:merge 0 0 1 zuul:enqueue 0 0 1 merger:update 0 0 1 zuul:promote 0 0 1 set_description:master 0 0 1 build:noop-check-communication 0 0 2 stop:master 0 0 1 . ^] telnet> quit Connection closed.
Enabling the dsvm-tempest-full Job in the Zuul Pipelines
Once you’ve successfully run the dsvm-tempest-full job manually, you should now enable this job in the appropriate Zuul pipelines. To do so, on the Jenkins master node, you will want to edit the etc/zuul/layout.yaml file in your data repository (don’t forget to git commit your changes after you’ve made them and push the changes to the location of your data repository’s canonical location).
If you used the example layout.yaml from my data repository and you’ve been following along this tutorial series, the projects section of your file will look like this:
projects:
- name: openstack-dev/sandbox
check:
# Remove this after successfully verifying communication with upstream
# and seeing a posted successful review.
- noop-check-communication
# Uncomment this job when you have a jenkins slave running and want to
# test a full Tempest run within devstack.
#- dsvm-tempest-full
gate:
# Remove this after successfully verifying communication with upstream
# and seeing a posted successful review.
- noop-check-communication
# Uncomment this job when you have a jenkins slave running and want to
# test a full Tempest run within devstack.
#- dsvm-tempest-full
To enable the dsvm-tempest-full Jenkins job to run in the check pipeline when a patch is received (or recheck comment added) to the openstack-dev/sandbox project, simply uncomment the line:
#- dsvm-tempest-full
And then reload Zuul and Zuul-merger:
sudo service zuul reload sudo service zuul-merger reload
From now on, new patches and recheck comments on the openstack-dev/sandbox project will fire the dsvm-tempest-full Jenkins job on your devstack slave node. 🙂 If your test run was successful, you will see something like this in your Jenkins console for the job run:

And you will note that on the patch that triggered your Jenkins job will show a successful comment, and a +1 Verified vote:

What Next?
From here, the changes you make to your Jenkins Job configuration files are up to you. The first place to look for ideas is the devstack-vm-gate.sh script. Look near the bottom of that script for a number of environment variables that you can set in order to tinker with what the script will execute.
If you are a Cinder storage vendor looking to test your hardware and associated Cinder driver against OpenStack, you will want to either make changes to the example dsvm-tempest-full or create a copy of that example job definition and customize it to your needs. You will want to make sure that Cinder is configured to use your storage driver in the cinder.conf file. You may want to create some script that copies most of what the devstack-vm-gate.sh script does, and call the devstack ini_set function to configure your storage driver, and then run devstack and tempest.
Publishing Console and Devstack Logs
Finally, you will want to get the log files that are collected by both Jenkins and the devstack run published to some external site. Folks at Arista have used dropbox.com to do this. I’ll leave it up to an exercise for the reader to set this up. Hint: that you will want to set the PUBLISH_HOST variable in your data repository’s vars.sh to a host that you have SCP rights to, and uncomment the publishers section in the example dsvm-tempest-full job:
# publishers: # - devstack-logs # In macros.yaml from os-ext-testing # - console-log # In macros.yaml from os-ext-testing
Final Thoughts
I hope this three-part article series has been helpful for you to understand the upstream OpenStack continuous integration platform, and instructional in helping you set up your own external testing platform using Jenkins, Zuul, and Jenkins Job Builder, and Devstack-Gate. Please do let me know if you run into issues. I will post some updates to the Troubleshooting section above when I hear from you and (hopefully help you resolve any problems).