In a conversation on Twitter, Lydia Leong stated something that I’ve heard from a number of industry folks and OpenStack insiders alike:
The core needs to be small, rock-solid stable, and readily extensible.
I responded:
Depends on what you mean by “core” 🙂 I think that term has been abused.
It’s probably worth writing down a response that spans more than 140 characters, so I decided to write a post about why the term “core” is, indeed, abused, and some of my thoughts about Lydia’s pronouncement.
First, on specificity
In my years working in the cloud space, it has dawned on me that there really is no single way of looking at the cloud development and deployment space. As soon as one person (myself included) tries to describe with any detail what cloud systems are, invariably someone else will say “no, it’s not (just) that… it’s this as well.”
For instance, if I say that cloud is on-demand computing that gives application developers tools to drive their own deployment, someone will correctly point out that cloud is also hardware that has been virtualized to fit budgetary and technological needs of an IT department.
Similarly, if I said that cloud was all about treating VMs as cattle, someone will rightly come along and say that legacy applications and “pet VMs” have as much of a right to benefit from virtualized infrastructure as those hipster-scale folks.

And, then John Dickinson will appropriately say, “hey, Jay, cloud isn’t all about compute, you know.” And of course, he’d be totally correct.
My point is that, well, cloud means something different to everyone. And there’s really nothing wrong with that. It just means that when you express an idea about the cloud space, you should qualify exactly what it is you are applying that idea to, and conversely, what you are not applying your idea to.
And, of course, Twitter, being limited in its conversational envelope size, is hardly an ideal medium to express grand ideas about a space such as “the cloud” that already suffers from a dearth of crisp definition.
On golf balls, layercake, and taxonomy
Forrester, Gartner and other companies obsessively attempt to categorize and rank companies and products in ways that they feel are helpful to their CIO/tech buyer audience. And that’s fine; everybody’s got to make a living out here.
But lately, it seems the OpenStack developer community has gotten gung-ho about categorizing various OpenStack projects. I want to summarize here some of the existing thoughts on the matter, before delving into my own personal opinions.
Late last year, Dean Troyer originally posted his ideas about categorizing projects within the OpenStack arena using a set of layers. His ideas were centered around finding a way to describe new projects in a technical (as opposed to trademark or political) sense, in order to more easily identify where the project fit in relation to other projects. The impetus for Dean’s “OpenStack Layers” approach was his work in DevStack, in trying to detect the boundaries and dependencies between components that DevStack configures.
Sean Dague more recently expanded on Dean’s ideas, attempting to further clarify where newer (since Dean’s post) incubated and integrated projects lie in the OpenStack layers. Monty Taylor and Robert Collins followed up Sean’s post with posts of their own, each attempting to further provide ways in which OpenStack projects may be grouped together.
Dean’s model had five simple layers:
- Layer 0: Operating Systems and Libraries — OS, database, message queue, Oslo, other libraries
- Layer 1: The Basics — Keystone, Glance, Nova
- Layer 2: Extending the Base — Cinder, Neutron, Swift, Ironic
- Layer 3: All the options — Ceilometer, Horizon
- Layer 4: Turtles all the way up — Heat, Trove, Zaqar, Designate
Sean’s model extended Dean’s, adding in a couple of the projects like Barbican that had not really been around at the time of Dean’s post, and calling the turtle layer “Consumption Services”:

Monty’s model grouped OpenStack projects in yet a different manner:
Layer #1The Only Layer — Any project that is needed to spin up a VM running WordPress on it. His list here is Keystone, Glance, Nova, Cinder, Neutron and Designate. Monty believes this is where the layer model falls apart, and all other terms should be simple “tags” that describe some aspect of a project- Tag: Cloud Native — Any project “that provide(s) features for end user applications which could be provided by services run within VMs instead.” Examples here are Trove and Swift. Trove provides managed databases in VMs instead of databases running on bare metal. Swift provides object storage instead of the user having to run their own bare-metal machines with lots of disk space.
- Tag: Operations — Any project that bridges functional gaps between various components for operators of OpenStack clouds. Examples here include Ceilometer and Ironic.
- Tag: User Interface — Any project that enhances the user interface to other OpenStack services. Examples here are Horizon, Heat, and the openstack-sdk

Thierry Carrez redefined Monty’s “Layer #1” as “Ring 0”. His depiction of OpenStack is like the construction of a golf ball, with a small rubber core and a larger plastic covering[1], rather than the layercake of Sean and Dean. In Thierry’s model, the OpenStack projects that would live in “Ring 0” would be the projects that would need to be “tightly integrated” and “limited-by-design”. All other projects would just live outside this Ring 0, but still be “in OpenStack”. Thierry also brings up the question of what to do about the concept of Programs, which to this date, are the official way in which the OpenStack community blesses teams of people working towards common missions. At least, that’s what Programs are supposed to be. In practice, they tend to be viewed as equal to the main project that the Program began life as.
Finally, Robert Collins’ take on the layers discussion brought up a couple interesting points about the importance of APIs vs implementation (which I will cover shortly) and that the “core” of OpenStack really is smaller than Monty envisioned, but Robert ended up with a taxonomy of OpenStack projects that was broken up by functional categories. There would be a set of teams that would select which projects implemented an API that belonged to one of the following functional categories:
- IaaS product: selects components from the tent to make OpenStack/IaaS
- PaaS product: selects components from the tent to make OpenStack/PaaS
- CaaS product: (containers)
- SaaS product: (storage)
- NaaS product: (networking – but things like NFV, not the basic Neutron we love today). Things where the thing you get is useful in its own right, not just as plumbing for a VM.
So why do we insist on categorizing these projects?
All of the above OpenStack leaders try to get at the fundamental question of what is the core of OpenStack? But, really, what is this obsession we have with shoving OpenStack projects into these broad categories? Why do we need to constantly define what this core thing is? And what does Lydia refer to when she says that the “core needs to be small, rock-solid stable, and readily extensible”?
I am going to posit that labeling some set of projects “the OpenStack Core” is actually not useful to any of our users[2], and that replacing overloaded terms such as “core” or “integrated” or “incubated” with a set of informative tags for each project will lead to a more enlightened OpenStack user community.
Monty started his blog post with a discussion about the different types of users that we serve in the OpenStack community. I think when we answer questions about OpenStack projects, we always need to keep in mind what information is actually useful to these different user groups, and why that information is useful. When we understand the characteristics that make a certain piece of information useful to a group of users, we can emphasize those characteristics in the language we use to describe OpenStack.
Operators
Let’s take the group of OpenStack users that Monty calls “deployers”, that I like to call “operators”. These are folks that have deployed OpenStack and are running an OpenStack cloud for one or more users. What kinds of information do these users crave? I can think of a number of questions that this user group frequently asks:
- Should I deploy OpenStack using an OpenStack distribution like RDO, or should I deploy OpenStack myself using something like DevStack or maybe the Chef cookbooks on Stackforge?
- Is the Icehouse version of Nova more stable than Havana?
- Does Ceilometer’s SQL driver handle 2000 or more VMs?
- What notification queues can my Nagios NPRE plugin monitor to get an early warning sign that something is degraded?
- Can my old Grizzly nova-network deployment be upgraded to Icehouse Neutron with no downtime to VM networking?
- What is the best way to diagnose data plane network connectivity issues with Havana Neutron deployments that use OpenVSwitch 1.11 and the older OpenVSwitch agent with ML2?
- Is Heat capable of supporting 100 concurrent users?
For operators, questions about OpenStack projects generally revolve around stability, performance & scalability and deployment & diagnostics. They want to know practical information on their options with regards to how they can deploy OpenStack, keep it up and running smoothly, and maintain it over time.
What does defining a set of “core OpenStack projects” give the operator user group? Nothing.
What might we be able to tag OpenStack projects with that would be of use to operators? Well, I think the answer to this question comes in the form of answers to the questions that these operators frequently ask. How’s this for a set of tags that might be useful to operators?
- included-in-$distribution-$version: Indicates a project has been packaged for inclusion in some OpenStack distribution. Examples: included-in-rdo-icehouse, included-in-uca-trusty, included-in-mos-5.1
- stability-$rating: Indicates the operator community’s viewpoint on the stability of a project. Examples: stability-experimental, stability-improved, stability-mature
- driver-$driver-experimental: Indicates the developers of driver $driver consider the code to be experimental. Examples: driver-sql-experimental, driver-docker-experimental
- puppet-tested: Indicates that Puppet modules exist in the
openstack/code namespace that are functionally tested to install and configure the service. Similar tags could exist for chef-tested or ansible-tested, etc - operator-docs[-$topic]: Indicates that there is Operator-specific documentation for the project, optionally with a $topic suffix. Examples: operator-docs-nagios, operator-docs-monitoring
- rally-verified-sla: Indicates the project has one or more Rally SLA definitions included in its gate testing platform
- upgrade-from-$version-(in-place|downtime-needed): Indicates a project can be upgraded with or without downtime from some previous $version. Examples: upgrade-from-icehouse-in-place, upgrade-from-juno-downtime-needed
I personally feel all of the above tags contain more useful information for operators than having a set of “core OpenStack projects”.
Application developers (end users and DevOps folks)
Monty calls this group of users “end users”. The end users of clouds are application developers and DevOps people who support the operation of an application on a cloud environment. Again, let’s take a look at what this group of users typically cares about, in the form of frequent questions that this user group poses:
- Does the Fog Ruby library support connecting to HP Helion?
- Can I use python-neutronclient to connect to RAX Cloud and if so, does it support all of Neutron’s Firewall API extensions?
- Can I use Zaqar to implement a simple RPC mechanism for my cloud application? Do any public clouds expose Zaqar?
- Can I develop my cloud application against a private OpenStack cloud created with DevStack and deploy the application on Amazon EC2 and S3?
- How can I deploy a WordPress blog for my pointy-haired boss in my company’s OpenStack private cloud in less than 15 minutes to get him off my back?
- Can I use Nagios to monitor my cloud application, or should I use Ceilometer for that?
What does defining a set of “core OpenStack projects” give the end user group? Nothing.
How about a set of informative tags instead?
- supported-on-$publiccloud: Indicates that $publiccloud supports the service. Examples: supported-on-rax, supported-on-hp
- cloud-native: Indicates the project implements a service designed for applications built for the cloud
- user-docs[-$topic]: Indicates there is documentation specifically for application developers around this project, optionally for a smaller $topic. Examples: user-docs-nagios, user-docs-fog, user-docs-wordpress
- compare-to-$subject: Indicates that the service provides similar functionality to $subject. Examples: compare-to-s3, compare-to-cloud-foundry
- compat-with-$api: Indicates the project exposes functionality that allows $api to be used to perform some native action. Examples: compat-with-ec2-2013.10.9, compat-with-glance-v2. Optionally consider a -with-docs suffix to indicate documentation on the compatibility exists
You will probably note that many of the tags for application developers involve the existence of documentation about compatibility with, or comparison to, other APIs or services. This is because docs really matter to application developers. API docs, tutorials, usage examples, SDK documentation. All of this stuff is critical to driving strong adoption of OpenStack with cloud app developers. The move to a documentation focus can and should start with a simple set of user-focused tags that inform our application developer users about the existence of official documentation about the things they care about.
Packagers
The next group of OpenStack users are the packagers of the OpenStack projects. Monty calls this group of users the “distributors”. Folks who work on operating system packages of OpenStack projects and libraries, folks who work on the OpenStack distributions themselves, and folks who work on configuration management tool modules that install and configure an OpenStack project are all members of this user group. This group of users care about a number of things, such as:
- Does the Juno Nova release have support for the version of libvirt on Ubuntu Trusty Tahr?
- Does version X of the python-novaclient support version Y of the Nova REST API?
- Can Havana Nova speak with an Icehouse Glance server?
- Which Keystone token driver should I enable by default?
- Have database migrations for Icehouse Neutron been tested with PostgreSQL 9.3?
- Has the qpid message queue driver been tested with Juno Ceilometer?
What does defining a set of “core OpenStack projects” give the packager user group? Nothing.
You’ll notice that many of the concerns that packagers have revolve around two things: documentation around version dependencies and testing of various optional drivers or settings. What does a designation that a project is “in core OpenStack” answer for the packager? Really, nothing at all. A finer-grained source of information is what is desired. A set of tags would be much more useful:
- gated-with-$thing[-$version]: Indicates that patches to the project are gated on successful functional integration testing with $thing at an optional $version. Examples: gated-with-neutron, gated-with-postgresql, gated-with-glanceclient-1.1
- tested-with-$thing[-$version]: Indicates that functional integration tests are run post-merge against the project. Examples: tested-with-ceph, tested-with-postgresql-9.3
- driver-$driver-(recommended|default|gated|tested): Indicates a $driver is recommended for use, is the default, or is tested with some gate or post-merge integration tests. Examples: driver-sql-recommended, driver-mongodb-gated
OpenStack Developers
OK, so the final group of OpenStack users is the developers of the OpenStack projects themselves. This is the group that does the most squealing about categorizing projects in and out of the OpenStack tent. We’ve created a governance structure and organizational model that, as Zane Bitter said, is like the reverse of Conway’s law. We tend to box ourselves in because we focus so intently on creating these categories by which we group the OpenStack projects.
We created the terms “incubated” and “integrated” to ostensibly inform ourselves of which projects have aligned with the OpenStack governance model and infrastructure tooling processes. And then we created the gate as a model of those categories, without first asking ourselves whether the terms “incubated” and “integrated” were really serving a technically sound purpose. We group all the integrated and incubated projects together, saying that all these projects must integrate with each other in one giant, complex gate testing platform.
Zane thinks that is madness, and I tend to agree.
Personally, I feel we need to stop thinking in terms of “core” or “incubated” or “integrated” and instead stick to thinking about the projects that live in the OpenStack tent[3] in terms of the soft and hard dependencies that each project has to another. In graphical representation, the current set of OpenStack projects (that aren’t software libraries) might look something like this:
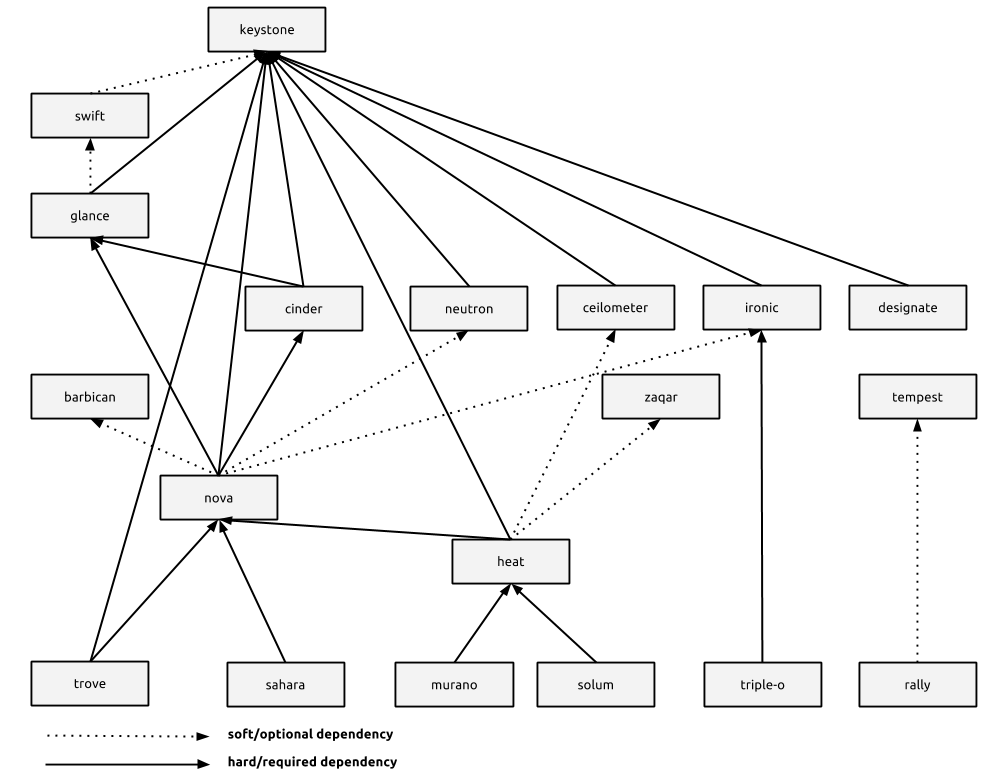
Converting that graphical representation to something machine-readable might produce a YAML snippet like this:
projects: - keystone - tempest - swift: soft: - keystone - glance: hard: - keystone soft: - swift ... - nova: hard: - keystone - glance - cinder soft: - neutron - ironic - barbican
The YAML above is nothing more than a set of tags that could be applied to OpenStack projects to inform developers about their relative dependency on other projects. This dependency graph information can then be used to construct a testing platform that should be more efficient than the current system that looks the way it does because we’ve insisted on using this single “integrated” category to describe the relationship of an OpenStack project with another.
So, my answer to Lydia
Seems I’ve yet again exceeded my 140 character limit. And I haven’t addressed Lydia’s point about the “core needs to be small, rock-solid stable, and readily extensible.” I think you can probably tell by now that I don’t think there is a useful way of denoting “a core OpenStack”. At least, not useful to our users. Does this mean that I disagree with Lydia’s sentiment about what is important for the OpenStack contributor community to focus on? Absolutely not.
So, in the spirit of specificity and useful taxonomic tagging, I will go further and make the following statements about the OpenStack community and code using Lydia’s words.
Our public REST APIs need to be designed to solve small problems
Right now, the public REST APIs of a number of OpenStack projects suffer from what I like to call “extension-itis”. Some of the REST APIs honestly feel like they were stitched together by a group of kindergartners, each trying to purposefully do something different than the last kid who attached their little piece of the quilt. APIs need to be small, simple, and clear. Why? Because they are our first impression, and OpenStack will live and die by the grace of the application developers that use our APIs.
We should have a working group composed of members of the Technical Committee, interested operators and end users, and API standards experts that control the public face of OpenStack: its HTTP REST APIs. This working group should have teeth to it, and be able to enforce a set of rules across OpenStack projects about API consistency, resource naming, clarity, discoverability and documentation
Our deployment tools need to be as rock-solid stable as any other part of our code
I’m not just talking about the official OpenStack Deployment Program here (Triple-O). I’m talking about the combination of Chef cookbooks, Puppet modules, Ansible playbooks, Salt state files, DevStack scripts, Mirantis FUEL deployment tooling, and the myriad other things that deploy and configure OpenStack services. They need to be tested in our continuous integration platform with the same zeal as everything else. As a community, we need to dedicate resources to make this a reality.
Our governance model needs to be readily extensible
Unfortunately, I believe our governance model and organizational structure has a tendency to reinforce the status quo and not adapt to changing times as quickly as it should. Examples of this rigidity are plenty. See, for example, the inability of the Technical Committee to come up with a single set of criteria for Zaqar’s graduation from incubation status. As a member of the Technical Committee, I can say I was pretty embarrassed at the way we treated the Zaqar contributor community. I’d love for the role of the Technical Committee to change from one of Judge to one of Advisor. The current Supreme OpenStack Court vision just reinforces the impression that our community cannot find a meaningful balance between progress and stability, and I for one refuse to admit that such a balance cannot be reached.
The current organization of official OpenStack Programs is something I also believe is no longer useful, and discourages our community from extending itself in the ways we should be extending. For example, we should be encouraging the sort of competition and pluralism that having multiple overlapping services like Ceilometer, Monasca, and Stacktach all under the OpenStack tent would bring.
There is no core

Finally, unless it’s not obvious, I don’t believe there is any OpenStack core. Or at least, that there’s any use to spending the effort required to concoct what it might be.
OK, I think that’s just about enough for one night of writing. Thanks very much if you made it all the way through. I look forward to your comments.
[1]OK, yes, golf balls have more than just a core and a larger plastic covering…just go with me on this and stop being so argumentative.
[2]Denoting some subset of OpenStack projects as “core” may be useful to industry pundits and marketing folks, but those aren’t OpenStack users.