Imagine that two colleagues, Alice and Bob, issue a command to launch a new virtual machine at approximately the same moment in time. Both Alice’s and Bob’s virtual machines must be given an IP address within the range of IP addresses granted to their project. Let’s say that range is 192.168.20.0/28, which would allow for a total of 16 IP addresses for virtual machines [1]. At some point during the launch sequence of these instances, Nova must assign one of those addresses to each virtual machine.
How do we prevent Nova from assigning the same IP address to both virtual machines?
In this blog post, I’ll try to answer the above question and shed some light on issues that have come to light about the way in which OpenStack projects currently solve (and sometimes fail) to address this issue.
Demonstrating the problem
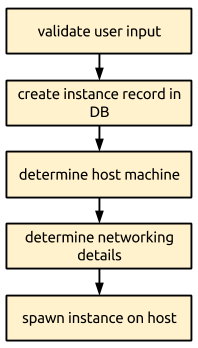
Dramatically simplified, the launch sequence of Nova looks like figure A. Of course, I’m leaving out hugely important steps, like the provisioning and handling of block devices, but the figure demonstrates the important steps in the launch sequence for the purposes of our discussion here. The specific step in which we find our IP address reservation problem is the determine networking details step.

Now, within the determine networking details step, we have a set of tasks that looks like figure B. All of the tasks except the last revolve around interacting with the Nova database [2]. The tasks are all pretty straightforward: we grab a record for a “free” IP address from the database and mark it “assigned” by setting the IP address record’s instance ID to the ID of the instance being launched, and the host field to the ID of the compute node that was selected during the determine host machine step in figure A. We then save the updated record to the database.
OK, so back to our problem situation. Imagine if Alice and Bob’s launch requests were made at essentially the same moment in time, and that both requests arrived at the start of the determine networking details step at the same point in time, but that the tasks from figure B are executed in an interleaved fashion between Alice and Bob’s requests like figure C shows.
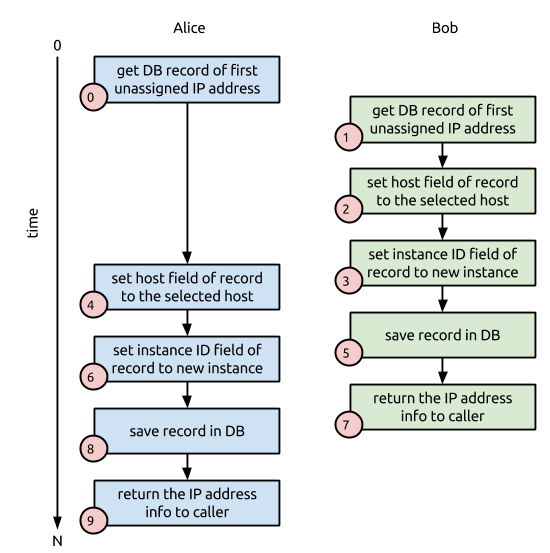
If you step through the numbered actions in both Alice and Bob’s request process, you will notice a problem. Actions #7 and #9 will both return the same IP address information to their callers. Worse, the database record for that single IP address will show the IP address is assigned to Alice’s instance, even though Bob’s instance was (very briefly) assigned to the IP address because the database update in action #5 occurred (and succeeded) before the database update in action #8 occurred (and also succeeded). In the words of Mr. Mackey, “this is bad, m’kay”.
There are a number of ways to solve this problem. Nova happens to employ a traditional solution: database-level write-intent locks.
Database-level Locking
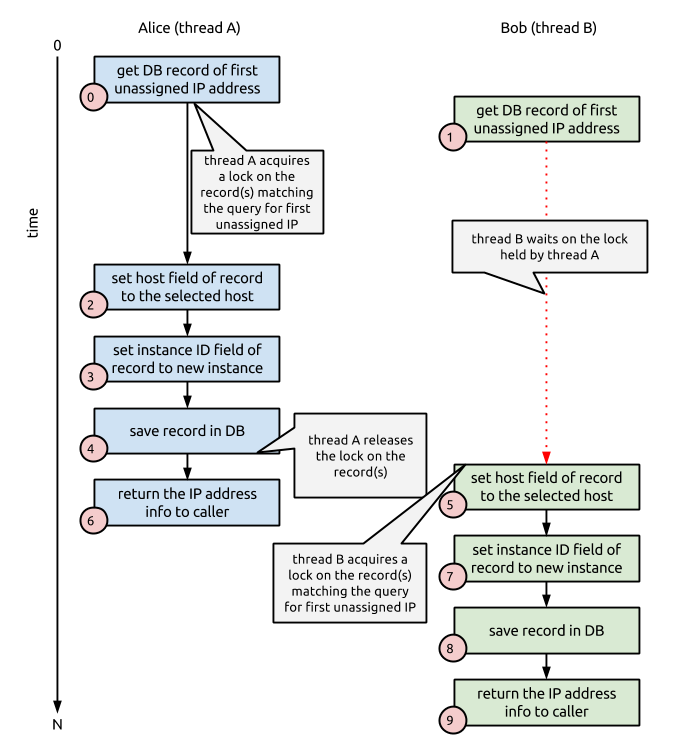
At its core, any locking solution is intended to protect some critical piece of data from simultaneous changes. Write-intent locks in traditional database systems are no different. One thread announces that it intends to change one or more records that it is reading from the database. The database server will mark the records in question as locked by the thread, and return the records to the thread. While these locks are held, any other thread that attempts to either read the same records with the intent to write, or write changes to those records, will get what is called a lock wait.
Only once the thread indicates that it is finished making changes to the records in question — by issuing a COMMIT statement — will the database release the locks on the records. What this lock strategy accomplishes is prevention of two threads simultaneously reading the same piece of data that they intend to change. One thread will wait for the other thread to finish reading and changing the data before its read succeeds. This means that using a write-intent lock on the database system results in the following order of events:
For MySQL and PostgreSQL, the SQL keyword that is used to indicate to the database server that the calling thread intends to change records that it is asking for is called SELECT ... FOR UPDATE.
Using a couple MySQL command-line client sessions, I’ll show you what affect this SELECT FOR UPDATE construct has on a normal MySQL database server (though the effect is identical for PostgreSQL). I created a test database table called fixed_ips that looks like the following:
CREATE TABLE `fixed_ips` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `host` INT(11) DEFAULT NULL, `instance_id` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; |
I then populate the table with a few records representing IP addresses, all “available” for an instance: the host and instance_id fields are set to NULL:
mysql> SELECT * FROM fixed_ips; +----+------+-------------+ | id | host | instance_id | +----+------+-------------+ | 1 | NULL | NULL | | 2 | NULL | NULL | | 3 | NULL | NULL | +----+------+-------------+ 3 rows in set (0.00 sec)
And now, here interleaved in time order in a tabular format, are the SQL commands executed in each of the sessions. Thread A is on the left, thread B on the right.
| Alice (thread A) | Bob (thread B) |
|---|---|
sessA>BEGIN;
Query OK, 0 rows affected (...)
sessA>SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2014-12-31 09:03:07 |
+---------------------+
1 row in set (0.00 sec)
sessA>SELECT * FROM fixed_ips
-> WHERE instance_id IS NULL
-> AND host IS NULL
-> ORDER BY id LIMIT 1
-> FOR UPDATE;
+----+------+-------------+
| id | host | instance_id |
+----+------+-------------+
| 2 | NULL | NULL |
+----+------+-------------+
1 row in set (...)
|
|
sessB>BEGIN;
Query OK, 0 rows affected (...)
sessB>SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2014-12-31 09:04:05 |
+---------------------+
1 row in set (0.00 sec)
sessB>SELECT * FROM fixed_ips
-> WHERE instance_id IS NULL
-> AND host IS NULL
-> ORDER BY id LIMIT 1
-> FOR UPDATE;
|
|
sessA>UPDATE fixed_ips
-> SET host = 42,
-> instance_id = 42
-> WHERE id = 2;
Query OK, 1 row affected (...)
Rows matched: 1 Changed: 1
sessA>COMMIT;
Query OK, 0 rows affected (...)
|
|
+----+------+-------------+ | id | host | instance_id | +----+------+-------------+ | 3 | NULL | NULL | +----+------+-------------+ 1 row in set (42.03 sec) sessB>COMMIT; Query OK, 0 rows affected (...) |
I’ve highlighted in red above the important things to note about the interplay between session A and session B. The 42.03 seconds is important: it shows the amount of time the SELECT ... FOR UPDATE statement waited on the write-intent locks held by session A. Secondly, the 3 returned by session B’s SELECT ... FOR UPDATE statement indicates that a different row was returned for the same query that session A issued. In other words, MySQL waited until session A issued a COMMIT before executing session B’s SELECT ... FOR UPDATE statement.
In this way, the write-intent locks constructed with the SELECT ... FOR UPDATE statement prevent the collision of threads changing the same record at the same time.
How locks “fail” with MySQL Galera Cluster
At the Atlanta design summit, I co-led an Ops Meetup session on databases and was actually surprised by my poll of who was using which database server for their OpenStack deployments. Out of approximately 220 people in the room, MySQL Galera Cluster was by far the most popular way of deploying MySQL for use by OpenStack services, with around 200 or so operators raising their hands that they used it. Standard MySQL was next, and there was one person using PostgreSQL.
MySQL Galera Cluster is a system that wraps the standard MySQL row-level binary replication log transmission with something called working-set replication, enabling synchronous replication between many nodes running the MySQL database server. Now, that’s a lot of fancy words to really say that Galera Cluster allows you to run a cluster of database nodes that do not suffer from replication slave lag. You are guaranteed that the data on disk on each of the nodes in a Galera Cluster is exactly the same.
One interesting thing about MySQL Galera Cluster is that it can efficiently handle writes to any node in the cluster. This is different from standard MySQL replication, which generally relies on a single master database server that handles writes and real-time reads, and one or more slave database servers that serve read requests from applications that can tolerate some level of lag between the master and slave. Many people refer to this setup as multi-master mode, but that is actually a misnomer, because with Galera Cluster, there is no such thing as a master and a slave. Every node in a cluster is the same. Each can apply writes coming to the node directly from a MySQL client. For this reason, I like to refer to such a setup as multi-writer mode.
This ability to have writes be directed to and processed by any node in the Galera Cluster is actually pretty awesome. You can direct a load balancer to spread read and write load across all nodes in the cluster, allowing you to scale writes as well as reads. This multi-writer mode is ideal for WAN-replicated environments, believe it or not, as long as the amount of data being written to is not crazy-huge (think: Ceilometer), because you can have application servers send writes to the closest database server in the cluster, and let Galera handle the efficiency of transmitting writesets across the WAN.
However, there’s a catch. Peter Boros, a principal architect at Percona, a company that makes a specialized version of Galera Cluster called Percona XtraDB Cluster, was actually the first to inform the OpenStack community about this catch — in the aforementioned Ops Meetup session. The problem with MySQL Galera Cluster is that it does not replicate the write-intent locks for SELECT ... FOR UPDATE statements. There’s actually a really good reason for this. Galera does not have any idea about the write-intent locks, because those locks are constructions of the underlying InnoDB storage engine, not the MySQL database server itself. So, there’s no good way for InnoDB to communicate to the MySQL row-based replication stream that write-intent locks are being held inside of InnoDB for a particular thread’s SELECT ... FOR UPDATE statement [3].
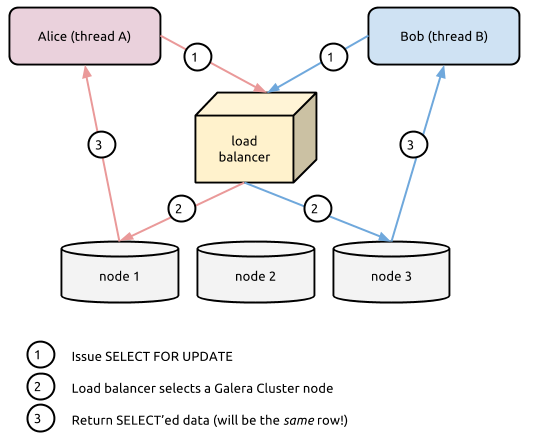
The ramifications of this catch are interesting, indeed. If two application server threads issue the same SELECT ... FOR UPDATE request to a load balancer at the same time, which directs each thread to different Galera Cluster nodes, both threads will return the exact same record(s) with no lock waits [4]. Figure E illustrates this phenomenon, with the circled 1, 2, and 3 events representing things occurring at exactly the same time (due to no locks being acquired/held).
One might be tempted to say that Galera Cluster, due to its lack of support for SELECT ... FOR UPDATE write-intent locks, is no longer ACID-compliant, since now two threads can simultaneously select the same record with the intent of changing it. And while it is indeed true that two threads can select the same record with the intent of changing it, it is extremely important to point out that Galera Cluster is still ACID-compliant.
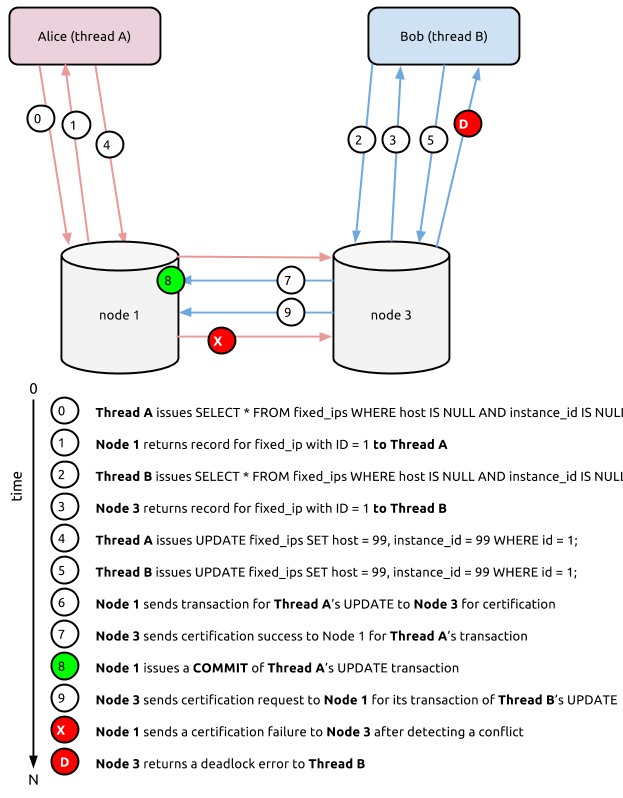
The reason is because even though two threads can simultaneously read the same record with the intent of changing it (which is the identical behaviour that would be seen if the FOR UPDATE was left off the SELECT statement), if both threads attempt to write a change to the same record via an UPDATE statement, either one or none of the threads would succeed in updating the record, but not both. The reason for this is in the way that Galera Cluster certifies a working set (the set of changes to data). If node 1 writes an update to disk, it must certify with a quorum of nodes in the cluster that its update does not conflict with updates to those nodes. If node 3 has begun changing the same row of data, but has not certified with the other nodes in the cluster for that working set, then it will fail to certify the original working set from node 1 and will send a certification failure back to node 1.
This certification failure manifests itself as a MySQL deadlock error, specifically error 1213, which will look like this:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
All nodes other than the one that first “won” — i.e. successfully committed and certified its transaction — will return this deadlock error to any other thread that attempted to change the same record(s) at the same time as the thread that “won”. Need a visual of all this interplay? Check out figure F, which I scraped together for the graphically-inclined.
If you ever wondered why, in the Nova codebase, we make prodigious use of a decorator called @_retry_on_deadlock in the SQLAlchemy API module, it is partly because of this issue. These deadlock errors can be consistently triggered by running load tests or things like Tempest that can put a load on the database that forces “hot spots” in the data to occur. This decorator does exactly what you’d think it would do: it retries the transaction if a deadlock error is returned from the database server.
So, given what we know about MySQL Galera Cluster, one thing we are trying to do is entirely remove any use of SELECT ... FOR UPDATE from the Nova code base. Since we know it doesn’t work the way people think it works on Galera Cluster, we might as well stop using this construct in our code. However, the retry-on-deadlock mechanism is actually not the most effective or efficient mechanism we could use to solve the concurrent update problems in the Nova code base. There is another technique, which I’ll call compare and swap, which offers a variety of benefits over the retry-on-deadlock technique.
Compare and swap
One of the drawbacks to the retry-on-deadlock method of handling concurrency problems is that it is reactive by nature. We essentially wrap calls that may tend to deadlock with a decorator that catches the deadlock error if it arises and retry the entire database transaction again. The problem with this is that the deadlock error that manifests itself from the Galera Cluster working set certification failure (see Figure F above) takes some non-insignificant amount of time to occur.
Think about it. A thread manages to start a write transaction on a Galera Cluster node. It writes the transaction on the local node and gets all the way up to the point of doing the COMMIT. At that point, the node sends out a certification request to each node in the cluster (in parallel). It must wait until a quorum of those nodes respond with a successful certification. If another node has an active working set that changes the same modified rows, then a deadlock will occur, and that deadlock will eventually bubble its way back to the caller, who will retry the exact same database transaction. All of these things, while individually very quick in Galera Cluster, do take some amount of time.
What if we used a technique that would allow us to structure our SQL statements in such a way that we can avoid the roundtrips from one Galera Cluster node to the other nodes? Well, there is.
Consider the following SQL statements, taken from the above CLI examples:
BEGIN; /* Grab the "first" unassigned IP address */ SELECT id FROM fixed_ips WHERE host IS NULL AND instance_id IS NULL ORDER BY id LIMIT 1 FOR UPDATE; /* Let's assume that the above query returned the fixed_ip with ID of 1 We now "assign" the IP address to instance #42 and on host #99 */ UPDATE fixed_ips SET host = 99, instance_id = 42 WHERE id = 1; COMMIT; |
Now, we know that the locks taken for the FOR UPDATE statement won’t actually be considered by any other nodes in a Galera Cluster, so we need to get rid of the use of SELECT ... FOR UPDATE. But, how can we structure things so that the SQL code sent to any node in the Galera Cluster will guarantee to us that we will neither stumble into a deadlock error and that the cluster node we end up executing our statements on will not need to contact any other node to determine that another thread has updated the same record during the time that we SELECT‘d our record and when we go to UPDATE it?
The answer lies in constructing an UPDATE statement that contains a WHERE clause that contains all the fields from the previously SELECT‘ed record, like so:
/* Grab the "first" unassigned IP address */ SELECT id FROM fixed_ips WHERE host IS NULL AND instance_id IS NULL ORDER BY id LIMIT 1; /* Let's assume that the above query returned the fixed_ip with ID of 1 We now "assign" the IP address to instance #42 and on host #99, but specify that the host and instance_id fields must match our original view of that record -- i.e., they must both be NULL */ UPDATE fixed_ips SET host = 99, instance_id = 42 WHERE id = 1 AND host IS NULL AND instance_id IS NULL; |
If we structure our application code so that it is executing the above SQL statements, each statement can be executed on any node in the cluster, without waiting for certification failures to occur before “knowing” if the UPDATE would succeed. Remember that working set certification in Galera only happens once the local node (i.e. the node originally receiving the SQL statement) is ready to COMMIT the changes. Well, if thread B managed to update the fixed_ip record with id = 1 in between the time when thread A does its SELECT and the time thread A does its UPDATE, then the WHERE condition:
WHERE id = 1 AND host IS NULL AND instance_id IS NULL; |
Will fail to select any any rows in the database to update, since host IS NULL AND instance_id IS NULL will no longer be true if another thread updated the record. We can catch this failure to update any rows in the database more efficiently than the certification timeout, since the thread that sent the UPDATE ... WHERE ... host IS NULL AND instance_id IS NULL statement will receive notification about no rows updated before any certification traffic would ever be generated (since there’s no certification needed if nothing was updated).
Do we still need a retry mechanism? Yes, of course we do, in order to retry the SELECT, then UPDATE ... WHERE statements when a previous UPDATE ... WHERE statement returned zero rows affected. The difference between this compare-and-swap approach and the brute-force retry-on-deadlock approach is that we’re no longer reacting to an exception being emitted after some timeout of certification, but instead being proactive and just structuring our UPDATE statement to pass in our previous view of the record we want to change, allowing for a tighter retry loop to occur (no timeout waits needed, simply detect whether rows_affected is greater than zero).
This compare and swap mechanism is what I describe in the lock-free-quota-management Nova blueprint specification. There’s been a number of mailing list threads and IRC conversations about this particular issue, so I figured I would write a bit and create some pretty graphics to illustrate the sequencing of events that occurs. Hope this has been helpful. Let me know if you have thoughts on the topic or see any errors in my work. Always happy for feedback.
[1] This is just for example purposes. Technically, such a CIDR would result in 13 available addresses in Nova, since addresses for the gateway, cloudpipe VPN, and broadcast addresses are reserved for use by Nova.
[2] We are not using Neutron in our example here, but the same general problem resides in Neutron’s IPAM code as is described in this post.
[3] Technically, there are trade-offs between pessimistic locking (which InnoDB uses locally) and optimistic locking (that Galera uses in its working-set certification. For an excellent read on the topic, check out Jay Janssen‘s blog article on multi-node writing and deadlocks in Galera.
[4] If both threads happened to hit the same Galera Cluster node, then the last thread to execute the SELECT ... FOR UPDATE would end up waiting for the locks (in InnoDB) on that particular cluster node.